I wanted to direct a colleague to a tutorial on Multicast that explained about IGMP Snooping and the IGMP Query function. But I couldn't find one. So I'm writing one with an expand scope.
Multicast is a method of network addressing
Normally, when a publisher sends a packet, that packet has a destination address of a specific receiver. The sending application essentially chooses which host to send to, and the network's job is to transport that packet to that host. With multicast, the destination address is NOT the address of a specific host. Rather, it is a "multicast group", where the word "group" means zero or more destination hosts. Instead of the publisher choosing which receivers should get the packet, the receivers themselves tell the network that they want to receive packets sent to the group.
For example, if I send to multicast group 239.1.2.3, I have no idea which or even how many receivers might get that packet. Maybe none at all. Or maybe hundreds. It depends on the receivers - any receiver that has joined group 239.1.2.3 will get a copy of the packet.
Layer 2 (Ethernet)
For this tutorial, layer 2 means Ethernet, and layer 3 means IP. Yes, there are other possibilities. No, I don't care. :-)
Multicast exists in Ethernet and IP. They are NOT the same thing!
In the old days of Ethernet, you had a coaxial cable that had taps on it (hosts connected to the taps). At any given point in time, only one machine could be sending on the cable, and the signal was seen by all machines attached to the same cable. The NIC's job was to look at each and every packet that came by and consume the ones that are addressed to that NIC, ignoring packets not addressed to the NIC.
Ethernet multicast was a very simple affair. The NIC could be programmed to consume packets from a small number of application-specified Ethernet multicast groups. Multicast packets, like all other packets, were seen by every NIC on the network, but only NICs programmed to look for a multicast group would consume packets sent to that group.
Ethernet multicast was not routable to other networks.
LAYER 3 (IP)
IP multicast was built on top of Ethernet multicast, but added a few things, like the ability to route multicast to other networks.
When routing multicast, you don't want to just send *all* multicast packets to *all* networks. That would waste too much WAN bandwidth. So the IGMP protocol was created. Among other things, IGMP provides a way for routers to be informed about multicast *interest* in each network. So if a router sees a multicast packet for group X, and it knows that a remote network has one or more hosts joined to that group, it will forward the packet to that network. (That network's router will then use Ethernet multicast to distribute the packet.)
To maintain the router's group interest table, IGMP introduced a "join" command by which a host on a network tells the routers that it is interested in group X. There is also an IGMP "leave" message for when the host loses interest.
But what if the host crashes without sending a "leave" message? Routers have a lifetime for the multicast routing table entries. After three minutes, the router will remove a multicast group from its table unless the entry is refreshed. So every minute, the router sends out an "IGMP Query" command and the hosts will respond according to the groups they are joined to. This keeps the table refreshed for groups that still have active listeners, but lets dead table entries time out.
If the network administrator forgets to configure the routers to run an IGMP Querier, after 3 minutes the router will stop forwarding multicast packets (multicast "deafness" across a WAN).
IGMP Snooping
As mentioned earlier, in the old days of coaxial Ethernet, every packet is sent to every host, and the host's NIC is responsible for consuming only those packets it needs. This limits the total aggregate capacity of the network to the NIC speed. Modern switches greatly boost network capacity by isolating traffic flows from each other, so that host A's sending to host B doesn't interfere with host C's sending to host D. The total aggregate bandwidth capacity is MUCH greater than the NIC's link speed.
Multicast is different. Layer 2 Ethernet doesn't know which hosts have joined which multicast groups, so by default older switches "flood" multicast to all hosts. So similar to coaxial Ethernet, the total aggregate bandwidth capacity for multicast is essentially limited to NIC link speed.
So they cheated a little bit. Even though IGMP is a layer 3 IP protocol, layer 2 Ethernet switches can be configured to passively observe ("snoop") IGMP packets. And instead of keeping track of which networks are interested in what groups, the switch keeps track of which individual hosts on the network are interested in which groups. When the switch has a multicast packet, it can send it only to those hosts that are interested. So now you can have multiple multicast groups carrying heavy traffic, and so long as a given host doesn't join more groups than its NIC can handle, you can have aggregate multicast traffic far higher than NIC link speeds.
As with routers, the switch's IGMP Snooping table is aged out after 3 minutes. A router's IGMP query accomplishes the same function with the switch; it refreshes the active table entries.
Note that a layer 2 Ethernet switch is supposed to be a passive listener to the IGMP traffic between the hosts and the routers. However, for the special case where a network has no multicast routing, the IGMP Querier function is missing. So switches that support IGMP Snooping also support an IGMP querier. If the network administrator forgets to configure IGMP Snooping to query, the switch will stop delivering multicast packets after 3 minutes (multicast "deafness" on the LAN).
Showing posts with label Multicast. Show all posts
Showing posts with label Multicast. Show all posts
Wednesday, June 3, 2020
Thursday, September 21, 2017
Solaris Multicast Deafness Bug
Once again, the mighty Dave Zabel (of two different fames) has found another Multicast-related bug, this time in Solaris. I think that recent versions of Solaris fix it, and I don't have the energy to track down *when* they fixed it, but if you have Solaris servers that you haven't kept updated for a while, you might have this bug.
DEAFNESS DEMONSTRATED
You'll need Informatica's "mtools" package for Solaris. These are great tools offered for free in both binary and source form at https://marketplace.informatica.com/solutions/informatica_mtools
And you'll need two hosts: A and B. Host B should be Solaris 6.10 that hasn't been updated in a long time. Host A can be anything.
1. On host A, run this:
msend 239.0.3.13 12000 15
2. On host B, open two windows. In the first, enter this:
mdump 239.0.3.13 12000
Admire the printouts of the multicast packets for a while. Isn't technology wonderful? :-)
3. In a second host B window, enter:
mdump 239.128.3.13 12000
Note that the first window continues to print, but the second window is silent. No surprise; it is listening to a different and unused multicast group! Of course it is silent.
4. Kill that second mdump.
WHOA! The first mdump stops printing! It went deaf to 239.0.3.13. When trying this same experiment on Linux, or on our Solaris 5.11 machines, it does not go deaf. But we have several old, non-updated 5.10 machines where the first mdump does go deaf on this step.
5. Enter:
netstat -g
The OS still thinks it is listening to the multicast group.
6. Enter:
snoop -P host 239.0.3.13
The packets are still being received! But they aren't being delivered to the first mdump.
7. Enter:
mdump 239.128.3.13 12000
WHOA! The first mdump starts printing again! The second mdump is still silent since there still isn't any traffic on its multicast group.
MAYBE IT'S MY PROBLEM?
Maybe PEBKAC? Or a bug in mtools?
Nope. Let's start over and try it again with a small change in step 3:
1. On host A, run this:
msend 239.0.3.13 12000 15
2. On host B, open two windows. In the first, enter this:
mdump 239.0.3.13 12000
3. In a second host B window, enter:
mdump 239.64.3.13 12000
See what I did there? I changed the 128 to 64. As before, the first window continues to print, but the second window is silent.
4. Kill that second mdump.
Lookie there! The first mdump continues to print the messages. No deafness.
WHAT'S GOING ON?
Well, I'm not sure, but I think it's got to be related to multicast group aliasing. Remember that there are 2**28 different IP multicast groups. But what about Ethernet? There are only 2**23 Ethernet multicast MAC addresses allocated for use by IP multicast. It turns out that 239.0.3.13 and 239.128.3.13 map to the same Ethernet multicast MAC address: 01-00-5E-00-03-13.
The IGMP protocol doesn't care about that; host B still tells the switch which multicast groups are subscribed, and it treats 239.0.3.13 and 239.128.3.13 as different. But when the IP layer interfaces with Ethernet, it needs to program the NIC with the same multicast MAC address for those two IP groups. And apparently older versions of Solaris didn't do the book keeping right.
I've tried this experiment on other OSes and they all work as you would expect (no deafness). Our Solaris 5.11 machine does it right. And even a recently-installed 5.10 system works right. But older systems that haven't been updated in a while all have this problem.
THE MORAL OF THE STORY
The obvious moral is to update your systems.
But even then, you should avoid using multicast groups that alias on top of each other. The whole point of multicast is that you don't receive packets that you aren't interested in. But if you have traffic published to both 239.0.3.13 and 239.128.3.13, a host subscribing to only one of them will get data for both. The IP layer will do the right thing (discard the undesired packets), but it still produces an unnecessary load.
ANY OTHER GOTCHAS?
Sure. Watch out for well-known and ad-hoc multicast protocols in the range 224.0.0.0 - 224.4.255.255. Are any of those in use anywhere on your network? No? Are you sure they never will be?
Look at the multicast group we tested with: 239.0.3.13. That aliases on top of 224.0.3.13, which is in an ad-hoc1 range labeled "RFE Generic Service". I don't know what that is (and Google doesn't seem to know either), but I'm thinking I want to avoid aliasing, even if low probability.
You should be fine if you use multicast groups between 239.0.5.0 - 239.127.255.255.
Oh, and update your systems too. Good hygiene and all that.
UPDATE: UPGRADING FIXES IT
We've upgraded one of our "problem servers" to the latest Solaris 5.11 and it fixed the deafness problem.
I'm not interested in figuring out exactly which minor release they fixed it in.
DEAFNESS DEMONSTRATED
You'll need Informatica's "mtools" package for Solaris. These are great tools offered for free in both binary and source form at https://marketplace.informatica.com/solutions/informatica_mtools
And you'll need two hosts: A and B. Host B should be Solaris 6.10 that hasn't been updated in a long time. Host A can be anything.
1. On host A, run this:
msend 239.0.3.13 12000 15
2. On host B, open two windows. In the first, enter this:
mdump 239.0.3.13 12000
Admire the printouts of the multicast packets for a while. Isn't technology wonderful? :-)
3. In a second host B window, enter:
mdump 239.128.3.13 12000
Note that the first window continues to print, but the second window is silent. No surprise; it is listening to a different and unused multicast group! Of course it is silent.
4. Kill that second mdump.
WHOA! The first mdump stops printing! It went deaf to 239.0.3.13. When trying this same experiment on Linux, or on our Solaris 5.11 machines, it does not go deaf. But we have several old, non-updated 5.10 machines where the first mdump does go deaf on this step.
5. Enter:
netstat -g
The OS still thinks it is listening to the multicast group.
6. Enter:
snoop -P host 239.0.3.13
The packets are still being received! But they aren't being delivered to the first mdump.
7. Enter:
mdump 239.128.3.13 12000
WHOA! The first mdump starts printing again! The second mdump is still silent since there still isn't any traffic on its multicast group.
MAYBE IT'S MY PROBLEM?
Maybe PEBKAC? Or a bug in mtools?
Nope. Let's start over and try it again with a small change in step 3:
1. On host A, run this:
msend 239.0.3.13 12000 15
2. On host B, open two windows. In the first, enter this:
mdump 239.0.3.13 12000
3. In a second host B window, enter:
mdump 239.64.3.13 12000
See what I did there? I changed the 128 to 64. As before, the first window continues to print, but the second window is silent.
4. Kill that second mdump.
WHAT'S GOING ON?
Well, I'm not sure, but I think it's got to be related to multicast group aliasing. Remember that there are 2**28 different IP multicast groups. But what about Ethernet? There are only 2**23 Ethernet multicast MAC addresses allocated for use by IP multicast. It turns out that 239.0.3.13 and 239.128.3.13 map to the same Ethernet multicast MAC address: 01-00-5E-00-03-13.
The IGMP protocol doesn't care about that; host B still tells the switch which multicast groups are subscribed, and it treats 239.0.3.13 and 239.128.3.13 as different. But when the IP layer interfaces with Ethernet, it needs to program the NIC with the same multicast MAC address for those two IP groups. And apparently older versions of Solaris didn't do the book keeping right.
I've tried this experiment on other OSes and they all work as you would expect (no deafness). Our Solaris 5.11 machine does it right. And even a recently-installed 5.10 system works right. But older systems that haven't been updated in a while all have this problem.
THE MORAL OF THE STORY
The obvious moral is to update your systems.
But even then, you should avoid using multicast groups that alias on top of each other. The whole point of multicast is that you don't receive packets that you aren't interested in. But if you have traffic published to both 239.0.3.13 and 239.128.3.13, a host subscribing to only one of them will get data for both. The IP layer will do the right thing (discard the undesired packets), but it still produces an unnecessary load.
ANY OTHER GOTCHAS?
Sure. Watch out for well-known and ad-hoc multicast protocols in the range 224.0.0.0 - 224.4.255.255. Are any of those in use anywhere on your network? No? Are you sure they never will be?
Look at the multicast group we tested with: 239.0.3.13. That aliases on top of 224.0.3.13, which is in an ad-hoc1 range labeled "RFE Generic Service". I don't know what that is (and Google doesn't seem to know either), but I'm thinking I want to avoid aliasing, even if low probability.
You should be fine if you use multicast groups between 239.0.5.0 - 239.127.255.255.
Oh, and update your systems too. Good hygiene and all that.
UPDATE: UPGRADING FIXES IT
We've upgraded one of our "problem servers" to the latest Solaris 5.11 and it fixed the deafness problem.
I'm not interested in figuring out exactly which minor release they fixed it in.
Monday, May 22, 2017
Some multicast programming tips
Never too old to learn. :-)
There are lots of multicast example programs out there, so I won't try to compete with them. But I did run across several things that weren't explained very well.
Single Socket, Multiple Groups
Yes, you can create a single socket and have it receive datagrams from multiple multicast groups. Just include multiple calls to:
setsockopt(recv_sock, IPPROTO_IP, IP_ADD_MEMBERSHIP, ...
Multiple Sockets, One Group per Socket
This is another common use case, where you create multiple sockets for receiving, with each socket joined to a different multicast group.
Binding the Receive Socket
Since a socket needs to be bound to a port to receive any kind of UDP datagram, multicast or unicast, you need to include a call to bind(). You pass in a sockaddr_in with the sin_port set as desired (remember to pass it in network order). But what about the sin_addr? What do you set that to?
Many people set it to INADDR_ANY, which is what I did in a recent program. But in the multiple sockets, different group per socket case, it had an unexpected side effect. All of my sockets were bound to the same destination port, but joined to different multicast groups. With sin_addr set to INADDR_ANY, the kernel took each received datagram, replicated it, and delivered a copy to *every* socket, even if the datagram's destination group is different from the one joined to the stocket! I.e. simply doing the IP_ADD_MEMBERSHIP on a socket didn't filter datagrams based on the desired group. When a multicast datagram was received, the kernel just used the destination port and delivered a copy to every UDP socket bound to that port and INADDR_ANY.
I had to do some extra searching to find out that you can set the bind's sin_addr to the multicast group. I have some reason to suspect that this is not portable across all operating systems, but at least it works on Linux. Now I can have 10 sockets, each bound to the same port (don't forget SO_REUSEADDR) but different multicast groups. When a multicast datagram is received, it is delivered *only* to the socket which is bound to the right port/multicast group pair.
Single Socket, Multiple Groups, reprise
So, what about the case where you have a single socket joined to multiple groups? In that case, you *do* want to use INADDR_ANY in the bind.
Mix and Match?
I guess this poses a restriction. You can't have, say, 2 sockets that you distribute 4 multicast groups across, with two groups each. Why would you want to do that? Maybe to load-balance across threads. But assuming they all want to bind to the same port, you can't do it. Setting the sin_addr to INADDR_ANY prevents filterig, and will mean that both sockets will receive a copy of every datagram sent. But you can't set sin_addr to multiple multicast groups.
So if you want to have multiple sockets, multiple groups, and the same destination port, you need to have one group per socket, and bind that socket to the group.
There are lots of multicast example programs out there, so I won't try to compete with them. But I did run across several things that weren't explained very well.
Single Socket, Multiple Groups
Yes, you can create a single socket and have it receive datagrams from multiple multicast groups. Just include multiple calls to:
setsockopt(recv_sock, IPPROTO_IP, IP_ADD_MEMBERSHIP, ...
Multiple Sockets, One Group per Socket
This is another common use case, where you create multiple sockets for receiving, with each socket joined to a different multicast group.
Binding the Receive Socket
Since a socket needs to be bound to a port to receive any kind of UDP datagram, multicast or unicast, you need to include a call to bind(). You pass in a sockaddr_in with the sin_port set as desired (remember to pass it in network order). But what about the sin_addr? What do you set that to?
Many people set it to INADDR_ANY, which is what I did in a recent program. But in the multiple sockets, different group per socket case, it had an unexpected side effect. All of my sockets were bound to the same destination port, but joined to different multicast groups. With sin_addr set to INADDR_ANY, the kernel took each received datagram, replicated it, and delivered a copy to *every* socket, even if the datagram's destination group is different from the one joined to the stocket! I.e. simply doing the IP_ADD_MEMBERSHIP on a socket didn't filter datagrams based on the desired group. When a multicast datagram was received, the kernel just used the destination port and delivered a copy to every UDP socket bound to that port and INADDR_ANY.
I had to do some extra searching to find out that you can set the bind's sin_addr to the multicast group. I have some reason to suspect that this is not portable across all operating systems, but at least it works on Linux. Now I can have 10 sockets, each bound to the same port (don't forget SO_REUSEADDR) but different multicast groups. When a multicast datagram is received, it is delivered *only* to the socket which is bound to the right port/multicast group pair.
Single Socket, Multiple Groups, reprise
So, what about the case where you have a single socket joined to multiple groups? In that case, you *do* want to use INADDR_ANY in the bind.
Mix and Match?
I guess this poses a restriction. You can't have, say, 2 sockets that you distribute 4 multicast groups across, with two groups each. Why would you want to do that? Maybe to load-balance across threads. But assuming they all want to bind to the same port, you can't do it. Setting the sin_addr to INADDR_ANY prevents filterig, and will mean that both sockets will receive a copy of every datagram sent. But you can't set sin_addr to multiple multicast groups.
So if you want to have multiple sockets, multiple groups, and the same destination port, you need to have one group per socket, and bind that socket to the group.
Friday, March 31, 2017
Cisco Eating Multicast Fragments???
UPDATE: after upgrading the IOS our "MDF" switch, this problem went away. None of my readers (all 2 of them?) have reported seeing this problem with their switches. So I think this issue is closed.
I think we've discovered a bug in our Cisco switch related to UDP multicast and IP fragmentation. Dave Zabel (of Windows corrupting UDP fame) did the initial detective work, and I did most of the analysis. And I'm not quite ready to declare victory yet, but I'm pretty sure we know roughly what is going on.
BOTTOM LINE:
It appears that Cisco is not paying proper attention to whether a packet is fragmented when checking the UDP destination port for the BFD protocol. The result is that it eats user packets that it misidentifies as being part of that protocol.
THE SETUP:
We have 4 Catalyst 3560 "LAB" switches (48 port) trunked to a Catalyst 4507 "MDF" switch. Our lab test machines are distributed across the LAB switches.
Our messaging software multicasts UDP datagrams. One of our regression tests involves sending messages of varying sizes with randomized data. We saw that occasionally, one of the messages would be lost. Doing packet captures showed that the missing datagram is NAKed and retransmitted multiple times, but the subscribing host never saw the datagram, even though it saw all the previous and subsequent datagrams. (This particular test does not send at a particularly stressful rate.)
Further investigation showed that some hosts always got the message in question, while others never got the message. Turns out that the hosts that got the message were on the same LAB switch as the sender. The hosts that didn't get the message were on a different switch.
I narrowed it down to a minimal test datagram of 1476 bytes. The first 1474 bytes can be any arbitrary values, but the last two bytes had to be either "0e c8" or "0e c9". Any datagram with either of those two problematic byte pairs at that offset will be lost. Note that the datagram will be split into 2 packets (IP fragments) by the sending host's IP stack. Strategically placed tcpdumps indicated that the first IP fragment always makes it to the receiver, but the second one seems to be eaten by our "MDF" switch.
There's nothing magic about the size 1476 - it can be larger and the problem still happens. 1476 is just the smallest datagram which demonstrates the problem.
IP FRAGMENTATION:
IP fragmentation happens when UDP hands to IP a datagram that doesn't fit into a single MTU-sized Ethernet packet (1500 bytes). A UDP datagram consists of an 8-byte header, followed by up to 65,527 bytes of UDP payload. IP splits a large datagram up into fragments of 1480 bytes each and prepends its own 20-byte IP header to each fragment. But note that only the first fragment will contain the UDP header. So IP fragment #1 will hold the 8-byte UDP header and the first 1472 bytes of my datagram.
Since my test datagram is 1476 bytes long, IP fragment #2 will contain a 20-byte IP header followed by the last 4 bytes of my datagram.
I won't show you the first fragment of my test datagram because it's long and boring. And it is successfully handled by Cisco, so it's also not relevant.
Here's a tcpdump of the second fragment of my test datagram (test datagram bytes highlighted). Note that tcpdump includes a 14-byte Ethernet header in front of the 20-byte IP header, then the last 4 bytes of my test datagram, and finally 22 padding nulls to make up a minimum-size packet (those nulls are not counted as part of the IP payload).
07:56:38.518614 00:1e:c9:4e:a1:92 (oui Unknown) > 01:00:5e:65:03:01 (oui Unknown), ethertype IPv4 (0x0800), length 60: (tos 0x0, ttl 2, id 2132, offset 1480, flags [none], proto: UDP (17), length: 24) 10.29.3.88 > 239.101.3.1: udp
0x0000: 0100 5e65 0301 001e c94e a192 0800 4500 ..^e.....N....E.
0x0010: 0018 0854 00b9 0211 afed 0a1d 0358 ef65 ...T.........X.e
0x0020: 0301 0000 0ec8 0000 0000 0000 0000 0000 ................
0x0030: 0000 0000 0000 0000 0000 0000 ............
This is the packet which is successfully received by hosts on the same switch as the sender, but is never received by hosts on a different switch. Change the "0e c8" byte pair to, for example, "1e c8" or "0e c7" and everything works fine - the packet is properly forwarded.
A CASE OF MISTAKEN IDENTITY?
In my problematic datagram, the last 4 bytes occupy the same packet position in fragment #2 as the UDP header in a non-fragmented packet. In particular, the byte pair "0e c8" occupies the same packet position as the UDP destination port in a non-fragmented packet. Those byte values correspond to port 3784, which is used by the BFD protocol. BFD is used to quickly detect failures in the path between adjacent forwarding switches and routers, so it is of special interest to our switches. (The other problematic byte pair "0e c9" corresponds to port 3785, which is also used by BFD.)
So, when a LAB switch sends fragment #2 to the MDF, it looks like MDF is checking the UDP port WITHOUT looking at the IP header's "Fragment Offset" field. It should only look for UDP port if the fragment offset is zero. Here's that packet again with the fragment offset highlighted:
07:56:38.518614 00:1e:c9:4e:a1:92 (oui Unknown) > 01:00:5e:65:03:01 (oui Unknown), ethertype IPv4 (0x0800), length 60: (tos 0x0, ttl 2, id 2132, offset 1480, flags [none], proto: UDP (17), length: 24) 10.29.3.88 > 239.101.3.1: udp
0x0000: 0100 5e65 0301 001e c94e a192 0800 4500 ..^e.....N....E.
0x0010: 0018 0854 00b9 0211 afed 0a1d 0358 ef65 ...T.........X.e
0x0020: 0301 0000 0ec8 0000 0000 0000 0000 0000 ................
0x0030: 0000 0000 0000 0000 0000 0000 ............
For most (non-fragmented) packets, that byte will be zero, and the UDP header will be present, in which case the 0ec8 would be the port number. The highlighted fragment offset of b9 hex is 185 decimal, and IP fragment offset is measured in units of 8-byte blocks, so the actual offset is 8*185=1480, which is tcpdump has for "offset".
It also seems strange to me that the switch ignores which multicast group I'm sending to. I can send to any valid multicast group, and the problematic packet will be eaten by the "MDF" switch. Shouldn't there be a specific multicast group for BFD? Maybe I found 2 bugs?
My employer has a support contract with Cisco, and I'm working with the internal network group to get a Cisco ticket opened. I'll update as I learn more, but it's slow climbing through the various levels of internal and external tech support, each one of whom starts out with, "are you sure it's plugged in?" It may take weeks to find somebody who even knows what IP fragmentation is.
TRY IT YOURSELF
I would love to hear from others who can try this out on their own networks. Grab the source files:
To build on Linux do:
gcc -o msend msend.c
gcc -o mdump mdump.c
Note that I've tried other operating systems (Widows and Solaris), with the same test results. This is not an OS issue.
For this test, the main purpose of mdump is to get the host to join the multicast group.
Choose three hosts: A, B, and C. Make sure A and B are on the same switch, and C is on a different switch. In my case, all three hosts are on the same VLAN; I don't know if that is significant. For this example, let's assume that the three hosts' IP addresses are 10.29.1.1, 10.29.1.2, and 10.29.1.3 respectively, and that all NICs are named "eth0".
Choose a multicast group and UDP port that aren't being used in your network. I chose 239.101.3.1 and 12000. I've tried others as well, with the same test results.
Note that the msend and mdump commands require you to put the hosts's primary IP address as the 3rd command-line parameter. This is because multicast needs to be told explicitly which interface to use (normal IP routing doesn't know the "right" interface to use).
Open a window to A, and two windows each for B and C. Enter the following commands:
B1: ./mdump 239.101.3.1 12000 10.29.1.2
B2: tcpdump -i eth0 -s2000 -vvv -XX -e host 239.101.3.1
C1: ./mdump 239.101.3.1 12000 10.29.1.3
C2: tcpdump -i eth0 -s2000 -vvv -XX -e host 239.101.3.1
A: ./msend 239.101.3.1 12000 10.29.1.1
The "msend" command sends two datagrams. The first one is small and gives the sending host's name. The second one is the 1476-byte datagram, whose second fragment gets eaten by the Cisco "MDF" switch.
Window B1 should show both datagrams fully received.
B2 should show 3 packets:
1. The short packet with the host name.
2. Fragment #1 of the long packet
3. Fragment #2 of the long packet
C1 should only show the first datagram.
C2 should show 2 packets:
1. The short packet with the host name.
2. Fragment #1 of the long packet.
Fragment #2 is missing from C2, presumably eaten by the "MDF" switch.
Fragment #2 is missing from C2, presumably eaten by the "MDF" switch.
Note that the two "tcpdump" windows might show additional packets, which are for the "igmp" protocol, and are unrelated to the test. If I had more time, I would figure out how to get "tcpdump" to ignore them.
Thursday, October 15, 2015
Windows corrupting UDP datagrams
We just discovered that under a somewhat unlikely set of circumstances, Microsoft's Windows 7 (SP 1) will corrupt outgoing UDP datagrams. I have a simple demonstration program ("rsend") which reliably reproduces the bug. (I'll be pointing my Microsoft contact at this blog post.)
This bug was discovered by a customer, and we were able to reproduce it locally. I wish I could take the credit, but my friend and colleague, Dave Zabel, did most of the detective work. And amazing detective work it was! But I'll leave that description for another day. Let's concentrate on the bug.
CIRCUMSTANCES FOR THE BUG
1. UDP protocol. (Duh!)
2. Multicast sends. (Does not happen with unicast UDP.)
3. A process on the same machine must be joined to the same multicast group as being sent.
4. Window's IP MTU size set to smaller than the default 1500 (I tested 1300).
5. Sending datagrams large enough to require fragmentation by the reduced MTU, but still small enough *not* to require fragmentation with a 1500-byte MTU.
With that mix, you stand a good chance of the outgoing data having two bytes changed. It seems to be somewhat dependent on the content of the datagram. For example, a datagram consisting mostly of zeros doesn't seem to get corrupted. But it's not that hard to find datagram content that *is* consistently corrupted, so my "rsend" demonstration program has one such datagram hard-coded.
Regarding #3, for convenience the rsend program contains code to join the multicast group, but I've also reproduced it without rsend joining, and instead running "mdump" in a different window.
Finally, be aware that I have not done a bunch of sensitivity testing. I.e. I haven't tried different datagram sizes, different multicast groups, different MTU settings, jumbo frames, etc. Nor did I try different versions of Windows (only 7), different NICs, etc. Sorry, I don't have time to experiment.
BUG DEMONSTRATION
This procedure assumes that you have a Windows machine with its MTU at its default of 1500. (You change it below.)
1. Build "rsend.c" on Windows with VS 2005. Here's how I build it (from a Visual Studio command prompt):
cl -D_MT -MD -DWIN32_LEAN_AND_MEAN -I. /Oi -Forsend.obj -c rsend.c
link /OUT:rsend.exe ws2_32.lib mswsock.lib /MACHINE:I386 /SUBSYSTEM:console /NODEFAULTLIB:LIBCMT rsend.obj
mt -manifest rsend.exe.manifest -outputresource:rsend.exe;1
2. Run the command, giving it the ip address of the windows machine's interface that you want the multicast to go out of. For single-homed hosts, just give it the IP address of the machine. For example:
rsend 10.1.2.3
To make the tool easy to use, it hard codes the multicast group 239.196.2.128 and destination port 12000.
3. On a separate machine, do a packet capture for that multicast group. Note that the packet capture utilities I know of (wireshark, tcpdump) do *not* tell the kernel to actually join the multicast group. I generally deal with this using the "mdump" tool. Run it in a separate window. For example:
mdump 239.196.2.128 12000
In the packet capture, look at the 1278th and 1279th bytes of the UDP datagram data: they should both be zero. Here they are, with a few bytes preceding them:
0x75,0x34,0x34,0xa4,0xc5,0xb4,0x00,0x00
NOTE: at this point, the datagram will fit in a single ethernet frame, so no IP fragmentation happens.
4. While rsend is running, open a command prompt with administrator privilege (right-click on "command prompt" icon and select "run as administrator") and enter:
netsh interface ipv4 set subinterface "Local Area Connection" mtu=1300 store=persistent
Like magic, bytes 1278 and 1279 of the outgoing UDP datagrams change their values! Note that with an MTU of 1300, this UDP datagram now needs to be fragmented. If using wireshark, you'll need to examine the *second* packet to see the entire UDP datagram and get to byte 1278. I consistently see 0x62,0x27, but that seems to be dependent on datagram content as well.
5. Undo the MTU change:
netsh interface ipv4 set subinterface "Local Area Connection" mtu=1500 store=persistent
Magically, the bytes go back to their correct values of 0x00,0x00.
Note: if you comment out the setsockopt of IP_ADD_MEMBERSHIP, the corruption will not happen. The multicast datagrams will still go out, but they will be undamaged when the MTU is reduced. The obvious suspect is the internal loopback.
SOLUTION
The only solution I know of is to leave the Windows IP MTU at its default of 1500.
WHY SET MTU 1300???
I don't know why our customer set it on one of his systems. But he said that he would just set it back to 1500, so it must not have been importat.
If you google "windows set mtu size" you'll find people asking about it. In many cases, the user is trying to reach a web site which is across a VPN or some other private WAN link which does not have an MTU of 1500. The way TCP works is that it tries to send segments (a TCP segment is basically an IP datagram) as large as possible while avoiding IP fragmentation. So a TCP instance sending data might start with a 1500-byte segment size. If a network hop in-transit cannot handle a segment that large, it has a choice: either fragment it or reject it. TCP explicitly sets an option to say, "do not fragment," so the network hop drops the segment. It is supposed to return an ICMP error, which the sender's TCP instance will use to reduce its segment size. This algorithm is known as TCP's "path MTU discovery".
But many network components either do not generate ICMP errors, or do not forward them. This is supposedly done in the name of "security" (don't get me started). This breaks path MTU discovery. But the segments are still being dropped, so eventually the TCP sender times out and the web site doesn't work. Apparently this is fairly rare, but it does happen. Hence the "set MTU" questions. If the user reduces IP's MTU setting, it artificially reduces the maximum segment size used by TCP. Do a bit of experimenting to find the right value, et Voila! (French for "finally, I can download porn!")
So, how could Microsoft possibly not find this during their extensive testing? Well first of all, UDP use is rare compared to TCP. Multicast UDP is even more rare. Sending UDP multicast datagrams larger than MTU is getting close to unicorn rare. And doing all that with the IP MTU set to a non-standard value? Heck, I consider myself to be a pretty rigorous tester, and I would never have tried that.
UDPATE:
Thanks to Mr. Anonymous for asking the question about NIC offloading. We had considered the question previously (see my response in the comments), but in composing my response, I got to thinking about the offset of the corruption.
It's always in the second packet of the fragmented datagram, and always at 1278. But that offset is with respect to the start of the UDP payload. What is the offset with respect to the start of the second packet? I didn't look at this before since Wireshark's ability to reassemble fragmented datagrams is so handy. But I went ahead and clicked the "Frame" tab and saw that the corruption happens at offset 40 from the start of the packet.
Guess where the UDP checksum belongs in an UNfragmented datagram! Yep, offset 40. Something decided to take the second packet of the fragmented datagram and insert a separate UDP checksum where it *should* go if it were not a fragment.
This still seems like a software bug in Windows. Sure, maybe the NIC is doing the actual calculation. Maybe it's not. But it only happens when IP is configured for a non-standard MTU. If I have MTU=1500 and I send a fragmented datagram, there is no corruption.
UPDATE 2:
I did some experimenting with datagram size and verified something that I suspected. When the MTU is set to 1300, the corruption only happens when the datagram size is such that a 1500-byte MTU would *not* fragment but a 1300-byte MTU does. I.e. there is a size range of 200 bytes (the difference between 1300 and 1500). This is another reason Microsoft's testers apparently didn't discover this. Even if they tested fragmentation with non-standard MTUs, would they think to test a size in that specific range? With the benefit of hindsight, sure, it's "obvious". But if you're just testing combinations of configurations, you would just pick the "send fragments" combination, which is probably chosen to fragment with MTU 1500. (FYI: I've updated the original post to refine the conditions of the bug.)
I'm normally not a Microsoft cheerleader, so it feels weird to be defending them on this bug. :-)
UPDATE 3:
Since we noticed that the corruption always happens at offset 40 in the second packet, I decreased the size of the datagram to only include half of the corrupted pair. Sure enough, the last byte of the datagram got corrupted. An the second corrupted byte? Who knows. I kind of hoped it would corrupt something in Windows and maybe blue-screen it, but no such luck. I didn't "see" any misbehavior.
Does that mean there *was* no misbehavior? NO! The outgoing datagrams suddenly had bad checksums! Meaning that the mdump tool stopped receiving them since Linux discards datagrams with bad checksums. But tcpdump captures the packets *before* UDP discards them, so you can see the bad checksums.
I kept decreasing the size of the datagram till it was 1273 bytes. That still triggers fragmentation when MTU=1300. The outgoing datagrams had no visible corruption but had bad checksums. Reduce one more byte, and the datagram fits in one packet. Suddenly the checksums are OK.
I tried a few things, like sending packets hard, and varying their sizes, but other than the bad checksums I could not see any obvious Windows misbehavior.
I guess my days as a white-hat hacker are over before they started. (Did I get the tenses right on that sentence?)
Well, I think I'm done experimenting. If anybody else reproduces it, please let me know your Windows version.
UPDATE 4:
I heard back from my contact at MS. He said:
REDDIT:
Finally, Hi Reddit users! Thanks for pushing the hits on this post to many times the total hit count for the whole rest of the blog. :-) I read the comments and saw that my first update had already been noticed by somebody else.
Also, something a lot of Reddit comments have fixated on is my claim that UDP multicast is rare. I meant that the number of programs (and programmers) that use it is very small compared to all software, not that multicast is hardly ever used. As pointed out, there are several areas of network infrastructure which are multicast-based, so it gets used all the time. My point is that the number of programmer-hours spent *writing and testing* multicast-based software is very small compared to the overall networking software field. And as such, it tends not to be as burned-in as, say, TCP.
Also, in most multicast software that I have learned the guts of, the programmer makes sure that datagram sizes are kept small so as to avoid fragmentation. This seems to be due to the commonly-held idea that you should *never* let IP fragment, which I think comes from the fact that, at least historically, router performance is hurt if it has to perform fragmentation while a datagram is in transit. I'm not sure if this is still true for modern routers, but historically fragmentation needed to be handled by the supervisory processor. For the odd packet every now and then, no problem. For high-rate data flows, it can kill a router.
That seems to be the basis on which a lot of multicast software avoids fragmentation, preferring instead to split large messages into multiple datagrams. But this reasoning is often not applicable. Our software intended primarily to be used within a single data center. When we send a 2K datagram, no router needs to worry about fragmenting it; the sending host's IP stack splits the datagram into packets before they hit the wire. The intermediate switches and routers all have 1500 MTU, allowing the packets to traverse unmolested. The final receiving host(s) reassemble and pass the datagram to user space. This has a noticeable advantage for high-performance applications since the same amount of user data is passed with fewer system calls (the overhead of switching between user and kernel space is significant).
So while I'm sure our software is not alone in sending fragmented multicast datagrams, I stand behind my claim that sending fragmented multicast is relatively rare.
Regarding #3, for convenience the rsend program contains code to join the multicast group, but I've also reproduced it without rsend joining, and instead running "mdump" in a different window.
Finally, be aware that I have not done a bunch of sensitivity testing. I.e. I haven't tried different datagram sizes, different multicast groups, different MTU settings, jumbo frames, etc. Nor did I try different versions of Windows (only 7), different NICs, etc. Sorry, I don't have time to experiment.
BUG DEMONSTRATION
This procedure assumes that you have a Windows machine with its MTU at its default of 1500. (You change it below.)
1. Build "rsend.c" on Windows with VS 2005. Here's how I build it (from a Visual Studio command prompt):
cl -D_MT -MD -DWIN32_LEAN_AND_MEAN -I. /Oi -Forsend.obj -c rsend.c
link /OUT:rsend.exe ws2_32.lib mswsock.lib /MACHINE:I386 /SUBSYSTEM:console /NODEFAULTLIB:LIBCMT rsend.obj
mt -manifest rsend.exe.manifest -outputresource:rsend.exe;1
2. Run the command, giving it the ip address of the windows machine's interface that you want the multicast to go out of. For single-homed hosts, just give it the IP address of the machine. For example:
rsend 10.1.2.3
To make the tool easy to use, it hard codes the multicast group 239.196.2.128 and destination port 12000.
3. On a separate machine, do a packet capture for that multicast group. Note that the packet capture utilities I know of (wireshark, tcpdump) do *not* tell the kernel to actually join the multicast group. I generally deal with this using the "mdump" tool. Run it in a separate window. For example:
mdump 239.196.2.128 12000
In the packet capture, look at the 1278th and 1279th bytes of the UDP datagram data: they should both be zero. Here they are, with a few bytes preceding them:
0x75,0x34,0x34,0xa4,0xc5,0xb4,0x00,0x00
NOTE: at this point, the datagram will fit in a single ethernet frame, so no IP fragmentation happens.
4. While rsend is running, open a command prompt with administrator privilege (right-click on "command prompt" icon and select "run as administrator") and enter:
netsh interface ipv4 set subinterface "Local Area Connection" mtu=1300 store=persistent
Like magic, bytes 1278 and 1279 of the outgoing UDP datagrams change their values! Note that with an MTU of 1300, this UDP datagram now needs to be fragmented. If using wireshark, you'll need to examine the *second* packet to see the entire UDP datagram and get to byte 1278. I consistently see 0x62,0x27, but that seems to be dependent on datagram content as well.
5. Undo the MTU change:
netsh interface ipv4 set subinterface "Local Area Connection" mtu=1500 store=persistent
Magically, the bytes go back to their correct values of 0x00,0x00.
Note: if you comment out the setsockopt of IP_ADD_MEMBERSHIP, the corruption will not happen. The multicast datagrams will still go out, but they will be undamaged when the MTU is reduced. The obvious suspect is the internal loopback.
SOLUTION
The only solution I know of is to leave the Windows IP MTU at its default of 1500.
WHY SET MTU 1300???
I don't know why our customer set it on one of his systems. But he said that he would just set it back to 1500, so it must not have been importat.
If you google "windows set mtu size" you'll find people asking about it. In many cases, the user is trying to reach a web site which is across a VPN or some other private WAN link which does not have an MTU of 1500. The way TCP works is that it tries to send segments (a TCP segment is basically an IP datagram) as large as possible while avoiding IP fragmentation. So a TCP instance sending data might start with a 1500-byte segment size. If a network hop in-transit cannot handle a segment that large, it has a choice: either fragment it or reject it. TCP explicitly sets an option to say, "do not fragment," so the network hop drops the segment. It is supposed to return an ICMP error, which the sender's TCP instance will use to reduce its segment size. This algorithm is known as TCP's "path MTU discovery".
But many network components either do not generate ICMP errors, or do not forward them. This is supposedly done in the name of "security" (don't get me started). This breaks path MTU discovery. But the segments are still being dropped, so eventually the TCP sender times out and the web site doesn't work. Apparently this is fairly rare, but it does happen. Hence the "set MTU" questions. If the user reduces IP's MTU setting, it artificially reduces the maximum segment size used by TCP. Do a bit of experimenting to find the right value, et Voila! (French for "finally, I can download porn!")
So, how could Microsoft possibly not find this during their extensive testing? Well first of all, UDP use is rare compared to TCP. Multicast UDP is even more rare. Sending UDP multicast datagrams larger than MTU is getting close to unicorn rare. And doing all that with the IP MTU set to a non-standard value? Heck, I consider myself to be a pretty rigorous tester, and I would never have tried that.
UDPATE:
Thanks to Mr. Anonymous for asking the question about NIC offloading. We had considered the question previously (see my response in the comments), but in composing my response, I got to thinking about the offset of the corruption.
It's always in the second packet of the fragmented datagram, and always at 1278. But that offset is with respect to the start of the UDP payload. What is the offset with respect to the start of the second packet? I didn't look at this before since Wireshark's ability to reassemble fragmented datagrams is so handy. But I went ahead and clicked the "Frame" tab and saw that the corruption happens at offset 40 from the start of the packet.
Guess where the UDP checksum belongs in an UNfragmented datagram! Yep, offset 40. Something decided to take the second packet of the fragmented datagram and insert a separate UDP checksum where it *should* go if it were not a fragment.
This still seems like a software bug in Windows. Sure, maybe the NIC is doing the actual calculation. Maybe it's not. But it only happens when IP is configured for a non-standard MTU. If I have MTU=1500 and I send a fragmented datagram, there is no corruption.
UPDATE 2:
I did some experimenting with datagram size and verified something that I suspected. When the MTU is set to 1300, the corruption only happens when the datagram size is such that a 1500-byte MTU would *not* fragment but a 1300-byte MTU does. I.e. there is a size range of 200 bytes (the difference between 1300 and 1500). This is another reason Microsoft's testers apparently didn't discover this. Even if they tested fragmentation with non-standard MTUs, would they think to test a size in that specific range? With the benefit of hindsight, sure, it's "obvious". But if you're just testing combinations of configurations, you would just pick the "send fragments" combination, which is probably chosen to fragment with MTU 1500. (FYI: I've updated the original post to refine the conditions of the bug.)
I'm normally not a Microsoft cheerleader, so it feels weird to be defending them on this bug. :-)
UPDATE 3:
Since we noticed that the corruption always happens at offset 40 in the second packet, I decreased the size of the datagram to only include half of the corrupted pair. Sure enough, the last byte of the datagram got corrupted. An the second corrupted byte? Who knows. I kind of hoped it would corrupt something in Windows and maybe blue-screen it, but no such luck. I didn't "see" any misbehavior.
Does that mean there *was* no misbehavior? NO! The outgoing datagrams suddenly had bad checksums! Meaning that the mdump tool stopped receiving them since Linux discards datagrams with bad checksums. But tcpdump captures the packets *before* UDP discards them, so you can see the bad checksums.
I kept decreasing the size of the datagram till it was 1273 bytes. That still triggers fragmentation when MTU=1300. The outgoing datagrams had no visible corruption but had bad checksums. Reduce one more byte, and the datagram fits in one packet. Suddenly the checksums are OK.
I tried a few things, like sending packets hard, and varying their sizes, but other than the bad checksums I could not see any obvious Windows misbehavior.
I guess my days as a white-hat hacker are over before they started. (Did I get the tenses right on that sentence?)
Well, I think I'm done experimenting. If anybody else reproduces it, please let me know your Windows version.
UPDATE 4:
I heard back from my contact at MS. He said:
We've looked into this, and see what is happening. If the customer needs to pursue this rather than using a work around (e.g. not setting the MTU size on the loopback path to a different size than the non-loopback interface, etc.) they will need to open a support ticket. Thank you for letting me know about this."Which I suspect translates to, "We'll fix it in a future version, but not urgently. If you need urgency, pay for support." :-)
REDDIT:
Finally, Hi Reddit users! Thanks for pushing the hits on this post to many times the total hit count for the whole rest of the blog. :-) I read the comments and saw that my first update had already been noticed by somebody else.
Also, something a lot of Reddit comments have fixated on is my claim that UDP multicast is rare. I meant that the number of programs (and programmers) that use it is very small compared to all software, not that multicast is hardly ever used. As pointed out, there are several areas of network infrastructure which are multicast-based, so it gets used all the time. My point is that the number of programmer-hours spent *writing and testing* multicast-based software is very small compared to the overall networking software field. And as such, it tends not to be as burned-in as, say, TCP.
Also, in most multicast software that I have learned the guts of, the programmer makes sure that datagram sizes are kept small so as to avoid fragmentation. This seems to be due to the commonly-held idea that you should *never* let IP fragment, which I think comes from the fact that, at least historically, router performance is hurt if it has to perform fragmentation while a datagram is in transit. I'm not sure if this is still true for modern routers, but historically fragmentation needed to be handled by the supervisory processor. For the odd packet every now and then, no problem. For high-rate data flows, it can kill a router.
That seems to be the basis on which a lot of multicast software avoids fragmentation, preferring instead to split large messages into multiple datagrams. But this reasoning is often not applicable. Our software intended primarily to be used within a single data center. When we send a 2K datagram, no router needs to worry about fragmenting it; the sending host's IP stack splits the datagram into packets before they hit the wire. The intermediate switches and routers all have 1500 MTU, allowing the packets to traverse unmolested. The final receiving host(s) reassemble and pass the datagram to user space. This has a noticeable advantage for high-performance applications since the same amount of user data is passed with fewer system calls (the overhead of switching between user and kernel space is significant).
So while I'm sure our software is not alone in sending fragmented multicast datagrams, I stand behind my claim that sending fragmented multicast is relatively rare.
Monday, February 3, 2014
Socket buffers: more complicated than you think
If you are receiving UDP datagrams (multicast or unicast, no difference), how much socket buffer does a datagram consume? I.e. how many datagrams of a particular size can you fit in a socket buffer configured for a given size?
Well ... it's complicated.
I've tried some experiments on two of our Linux systems, and encountered some surprises. Note that my experiments were performed with modified versions of the msend and mdump tools, i.e. simple UDP with no higher-level protocol on top of it. (See my Github project for my modified versions.) The modified mdump command sets up the socket, prints a prompt, and waits for the user to hit return before entering the receive loop. I had msend sending 500 messages with 10 ms between sends (nice and slow so as not to overrun the NIC). Since the mdump is not yet in its receive loop, the datagrams are stored in the socket buffer. When the send finishes, I hit return on mdump, which enters the receive loop and empties the socket buffer, collecting statistics. Then I hit control-c on mdump, and it reports the number of messages and bytes received. Finally, I did experiments on both unicast and multicast; the results are the same.
Here are some results for a two-system test, sending from host "orion", receiving on host "saturn". The message sizes and bytes received shown are for UDP payload. Receive socket buffer configured for 100,000 bytes. Note that 1472 is the largest UDP payload which can be sent in a single ethernet frame (i.e. no IP fragmentation).
message
size
|
messages
received
|
bytes
received
|
| 1472 | 61 | 89792 |
| 215 | 61 | 13115 |
| 214 | 157 | 33598 |
| 1 | 157 | 157 |
Interesting. The number of messages seems to not depend on message size, except for a discontinuity at 215 bytes. I checked a lot of other message sizes, and they all follow the pattern: 61 messages for sizes >= 215, 157 messages for sizes <= 214.
Now let's double the receiver socket to 200,000 bytes:
message
size
|
messages
received
|
bytes
received
|
| 1472 | 121 | 178112 |
| 215 | 121 | 26015 |
| 214 | 313 | 66982 |
| 1 | 313 | 313 |
The messages received are approximately doubled, with the discontinuity at the exact same message size. Cutting the original socket buffer in half to 50,000 approximately cuts the message counts in half, with the discontinuity at the same place (I won't bother including the table).
Now lets switch the roles: send from saturn, receive on orion. Socket buffer back to 100,000 bytes.
message
size
|
messages
received
|
bytes
received
|
| 1472 | 77 | 113344 |
| 215 | 77 | 16555 |
| 214 | 363 | 77682 |
| 1 | 363 | 363 |
The discontinuity is at the same place, but different numbers of messages are received. The linux kernel versions are very close to the same - Saturn is 2.6.32-358.6.1.el6.x86_64 and orion is 2.6.32-431.1.2.0.1.el6.x86_64. Both systems have 32 gig of memory and are using Intel 82576 NICs. Saturn has 2 physical CPUs with 6 cores each, and orion has 2 physical CPUs with 4 cores each and hyperthreading turned on. I'm don't know why they hold different numbers of messages in the same-sized socket buffer.
These machines also have 10G Solarflare NICs in them, so let's give that a try. Send from saturn, receive on orion, socket buffer 100,000 bytes.
These machines also have 10G Solarflare NICs in them, so let's give that a try. Send from saturn, receive on orion, socket buffer 100,000 bytes.
message
size
|
messages
received
|
bytes
received
|
| 1472 | 110 | 161920 |
| 1 | 110 | 110 |
Whoa! That's right - when using the Solarflare card, the socket buffer held more bytes of data than the configured socket buffer size! But this isn't necessarily unexpected; the man page for socket(7) says this about setting the receive socket buffer: "The kernel doubles this value (to allow space for bookkeeping overhead)". Finally, it's interesting that there is no discontinuity - 110 messages, regardless of size.
Let's stick with the Solarflare cards, and go back to orion sending, saturn receiving (still 100,000 byte socket buffer):
Let's stick with the Solarflare cards, and go back to orion sending, saturn receiving (still 100,000 byte socket buffer):
message
size
|
messages
received
|
bytes
received
|
| 1472 | 87 | 128064 |
| 1 | 87 | 87 |
Fewer messages, but still exceeds 100,000 bytes worth with large messages.
Now let's put both sender and receiver on saturn (loopback), with 100,000 byte socket buffer:
Now let's put both sender and receiver on saturn (loopback), with 100,000 byte socket buffer:
message
size
|
messages
received
|
bytes
received
|
| 1472 | 87 | 128064 |
| 582 | 87 | 50634 |
| 581 | 157 | 91217 |
| 70 | 157 | 10990 |
| 69 | 261 | 18009 |
| 1 | 261 | 261 |
Lookie there! Two discontinuities.
Someday maybe I'll try this on other OSes (our lab has Windows, Linux, Solaris, HP-UX, AIX, FreeBSD, MacOS). Don't hold your breath. :-)
I did try a bit with TCP instead of UDP. It's a little trickier since instead of generating loss, TCP flow controls. And you have to take into account the send-side socket buffer. And I wanted to force small segments (packets), so I set the TCP_NODELAY socket option (to disable Nagle's algorithm). The results were much more what one might expect - the amount buffered depended very little on the segment size. With 1400-byte messages, it buffered 141,400 bytes. With 100-byte messages, it buffered 139,400 messages. I suspect the reduction is due to more overhead bytes. (I didn't try it with different NICs or different hosts.)
The moral of the story is: the socket buffer won't hold as much UDP data as you think it will, especially when using small messages.
UPDATE: on a colleague's suggestion, I looked at the "recv-Q" values reported by netstat. On Linux, I sent a single UDP datagram with one payload byte. The "recv-Q" value reported was 1280 for an Intel NIC, and 2304 for a Solarflare NIC. When I set the socket buffer to 100,000 bytes and fill it with UDP datagrams, "recv-Q" reports a bit over 200,000 bytes - double the socket buffer size I specified. (Remember that socket(7) says that the kernel doubles the buffer size to allow space for bookkeeping overhead.)
Someday maybe I'll try this on other OSes (our lab has Windows, Linux, Solaris, HP-UX, AIX, FreeBSD, MacOS). Don't hold your breath. :-)
I did try a bit with TCP instead of UDP. It's a little trickier since instead of generating loss, TCP flow controls. And you have to take into account the send-side socket buffer. And I wanted to force small segments (packets), so I set the TCP_NODELAY socket option (to disable Nagle's algorithm). The results were much more what one might expect - the amount buffered depended very little on the segment size. With 1400-byte messages, it buffered 141,400 bytes. With 100-byte messages, it buffered 139,400 messages. I suspect the reduction is due to more overhead bytes. (I didn't try it with different NICs or different hosts.)
The moral of the story is: the socket buffer won't hold as much UDP data as you think it will, especially when using small messages.
UPDATE: on a colleague's suggestion, I looked at the "recv-Q" values reported by netstat. On Linux, I sent a single UDP datagram with one payload byte. The "recv-Q" value reported was 1280 for an Intel NIC, and 2304 for a Solarflare NIC. When I set the socket buffer to 100,000 bytes and fill it with UDP datagrams, "recv-Q" reports a bit over 200,000 bytes - double the socket buffer size I specified. (Remember that socket(7) says that the kernel doubles the buffer size to allow space for bookkeeping overhead.)
UPDATE2:I'm not the first one to wonder about this. See https://www.unixguide.net/network/socketfaq/5.9 (that info is for BSD, not Linux).
Sunday, December 2, 2012
Multicast Oddities
The operation of multicast is standardized, well-defined, and well-understood.
Or is it? (Insert ominous music here)
RFCs and other standards mostly apply to packets as they traverse the network. Network administrators take care of multicast infrastructure so that software developers usually don't have to worry about the subtleties of multicast connectivity and routing. However, what the operating system does inside a host is often not governed by formal standards. There are some corner cases related to multi-homed hosts where operating systems behave in non-intuitive or inconsistent ways that the software developer must be aware of.
In the scenarios shown below, we tested multicast connectivity with a set of simple multicast tools "msend" (for sending) and "mdump" (for receiving). See mtools for source and binaries for these programs. In all cases, the msends and mdumps use the same multicast groups and destination ports. The testing was done on four operating systems: Linux, Solaris-10, FreeBSD, and Windows.
SCENARIO 1: UN-ROUTED

In this scenario, two interfaces are used, one for sending multicast packets and the other for receiving them. In particular, this scenario assumes that the two networks attached to the interfaces are not routed, at least not for multicast.
The results of testing the scenario are what you would expect - the mdump does not receive the traffic. This is true for all four operating systems.
No surprise here, right? Well, hang on tight; things are about to get more interesting.
SCENARIO 2: ROUTED

In this scenario, the two networks are routed. I.e. multicast packets sent to network 1 are routed to network 2. One would expect that the mdump would now receive the packets, right?
It does for Solaris-10, FreeBSD, and Windows. However, when tested with Linux, the mdump stays silent. We ran "netstat -g" and the kernel thinks it is joined to the multicast group on Network 2, and a "tcpdump" (with promiscuous mode turned OFF) indicates that the packets are, in fact, being received by the kernel. But for some reason, the Linux kernel is discarding those packets.
I, for one, consider this to be a bug in Linux. It violates application portability. That is, if the mdump is run on a separate machine connected to network 2, the packets are received just fine. But run it on the same machine as the sender, and it stops working.
SCENARIO 3: ROUTED, EXTRA MDUMP

In this scenario, a second mdump is added, joining network 1. One would expect both mdumps to receive the multicast, and in fact they both do. So the only surprise here is that mdump2 appears to have "fixed" the Linux bug in scenario 2.
SCENARIO 4: UN-ROUTED, EXTRA MDUMP
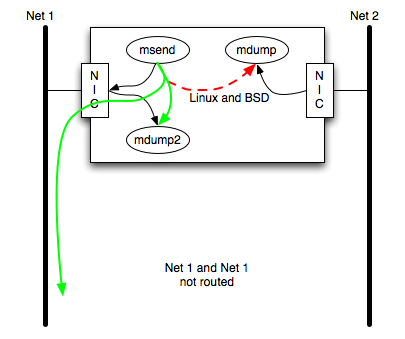
Things here get interesting again. Back to an unrouted scenario, with the second mdump. One would expect mdump2 to receive the data but not the original mdump.
This is what happens for Solaris-10 and WIndows. For Linux and FreeBSD, *both* mdumps receive the data. I consider this to be a bug for Linux and FreeBSD - why should an additional mdump change the behavior - but I consider it less serious than scenario 2's problem. In scenario 4, the problem is receiving more packets than expected, which could be filtered out by the application.
So, when dealing with multi-homed hosts, it is usually advisable to stick to a single interface if the networks are routed, or to use different multicast groups on each network if non-routed networks are used.
(BTW, this article was first published in 2009 on a different, now deleted, blog.)
Or is it? (Insert ominous music here)
RFCs and other standards mostly apply to packets as they traverse the network. Network administrators take care of multicast infrastructure so that software developers usually don't have to worry about the subtleties of multicast connectivity and routing. However, what the operating system does inside a host is often not governed by formal standards. There are some corner cases related to multi-homed hosts where operating systems behave in non-intuitive or inconsistent ways that the software developer must be aware of.
In the scenarios shown below, we tested multicast connectivity with a set of simple multicast tools "msend" (for sending) and "mdump" (for receiving). See mtools for source and binaries for these programs. In all cases, the msends and mdumps use the same multicast groups and destination ports. The testing was done on four operating systems: Linux, Solaris-10, FreeBSD, and Windows.
SCENARIO 1: UN-ROUTED
In this scenario, two interfaces are used, one for sending multicast packets and the other for receiving them. In particular, this scenario assumes that the two networks attached to the interfaces are not routed, at least not for multicast.
The results of testing the scenario are what you would expect - the mdump does not receive the traffic. This is true for all four operating systems.
No surprise here, right? Well, hang on tight; things are about to get more interesting.
SCENARIO 2: ROUTED
In this scenario, the two networks are routed. I.e. multicast packets sent to network 1 are routed to network 2. One would expect that the mdump would now receive the packets, right?
It does for Solaris-10, FreeBSD, and Windows. However, when tested with Linux, the mdump stays silent. We ran "netstat -g" and the kernel thinks it is joined to the multicast group on Network 2, and a "tcpdump" (with promiscuous mode turned OFF) indicates that the packets are, in fact, being received by the kernel. But for some reason, the Linux kernel is discarding those packets.
I, for one, consider this to be a bug in Linux. It violates application portability. That is, if the mdump is run on a separate machine connected to network 2, the packets are received just fine. But run it on the same machine as the sender, and it stops working.
SCENARIO 3: ROUTED, EXTRA MDUMP
In this scenario, a second mdump is added, joining network 1. One would expect both mdumps to receive the multicast, and in fact they both do. So the only surprise here is that mdump2 appears to have "fixed" the Linux bug in scenario 2.
SCENARIO 4: UN-ROUTED, EXTRA MDUMP
Things here get interesting again. Back to an unrouted scenario, with the second mdump. One would expect mdump2 to receive the data but not the original mdump.
This is what happens for Solaris-10 and WIndows. For Linux and FreeBSD, *both* mdumps receive the data. I consider this to be a bug for Linux and FreeBSD - why should an additional mdump change the behavior - but I consider it less serious than scenario 2's problem. In scenario 4, the problem is receiving more packets than expected, which could be filtered out by the application.
So, when dealing with multi-homed hosts, it is usually advisable to stick to a single interface if the networks are routed, or to use different multicast groups on each network if non-routed networks are used.
(BTW, this article was first published in 2009 on a different, now deleted, blog.)
Subscribe to:
Posts (Atom)
